

微博情感分析及爬取、水军检测稳定95%准确率
微博是什么我就不细说了,情绪分析的好处就是可以把用户分成各种类型,然后推送相应的广告,或者开动脑筋来发挥一下。在这个任务中我选择做的情绪分析是把用户分为真实用户和水军/营销粉。从大部分微博水军检测的论文来看,他们使用的方法主要是通过对用户的各种指标(关注度、粉丝数、平均发帖时间等)做逻辑回归来对用户进行分类,我觉得这种方法不够准确,而且对于不同的测试集会不稳定。我觉得这类任务需要NLP模型的帮助,因为水军和真人最大的区别就是写微博的行为习惯。
附github链接:github.com/timmmGZ/Wei...
我喜欢给一颗星来支持它。
重要的事情说三遍:
请使用google colab,由于需要使用xx,请在百度搜索“无xx,使用colab”
请使用google colab,由于需要使用xx,请在百度搜索“无xx,使用colab”
请使用google colab,由于需要使用xx,请在百度搜索“无xx,使用colab”
将xx改成其他的词。xx是什么我就不多说了,作为程序员的你应该自己就能猜到。
为了防止炼金术失控,本库使用了 Google Colab 的免费 TPU,请务必使用 Colab。下面是两个笔记本,这是训练和测试的过程
模型输入输出结构
输入
│── 用户信息指标:[关注数, 粉丝数, 互动数, 会员等级, 会员类别, 发微博总数, 微博等级, 是否认证, 认证类型]
│── 最新的第1条微博
│ │── 正文
│ │── 话题/超话
│ │── 被转发微博的特征:[话题/超话,有否视频及其关键信息?,有否照片及其关键信息?] 或者 "无转发"
│ └── 博文信息指标:[贴图数量,视频播放量,转发数,评论数,点赞数]
│── 最新的第2条微博
│── 最新的第...条微博
│── 最新的第n-1条微博
└── 最新的第n条微博
输出
│── 是真实用户
└── 是水军
模型架构
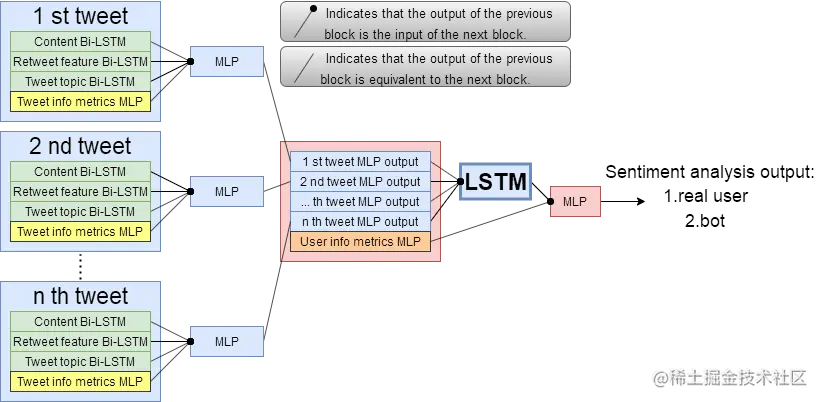
我认为,仅通过一条随机的微博来分析一个用户是不够的,我们需要分析来自单个用户的连续的微博。即对每 n 条微博并行进行情感分析(我使用 Bi-LSTM 模型),然后将这 n 个输出(尽量将它们视为一个句子的 token)放入网络中,最终得到分类。另外,人类有写作习惯,例如:有些人每三天发一次开心的内容,然后第二天发一次严肃的内容,而有些人可能每天只发悲伤的内容。假设小明(小明:“怎么又是我?我们去找小刚”)最近的 8 条微博将是[开心,开心,开心,严肃,开心,开心,开心,严肃],那么我们知道他每 8 条微博中就会有 2 条严肃的微博。 虽然[serious, serious, happy, happy, happy, happy, happy, happy, happy, happy, happy]的发帖类型频率是一样的,但是由于顺序不同,这个序列的“形状”是不一样的,我们也不能说这是小明的习惯。那么[happy, happy, serious, happy, happy, happy, serious, happy]只不过是左移了一个单位(多少个单位无所谓)的序列,但是它的“形状”是一样的,也可以说是小明的习惯。因此,用来连接n个输出的网络也会变成一个循环模型(我又用了LSTM)。由于这是一个嵌套并行的LSTM模型,为了防止梯度消失,我使用的激活函数大部分都是Tanh,并且在一些层上做了40%的Dropout,防止过拟合。下面是模型的结构。
爬虫
我手上有一个 user_id 数据集,里面有 568 个样本(274 个水军,294 个真实用户)。所有样本都经过人工检查标注,尽可能保证数据集的逻辑性和分布性,从而客观保证测试集准确率的公平性。将 user_id 数据集输入到我的爬虫代码中,爬虫代码会为模型输出一个新的数据集(如上文“模型输入结构”中所述)。同时,{正文} 和 {主题/超主题;转发微博特征} 的语法、词汇、句子长度等差异非常大,因此在做 embedding 的时候,我为它们分别创建了词典,这样也可以在以 one-hot encoding 输入 embedding 之前,先将 {主题/超主题;转发微博特征} 降维,可谓一举两得。
部分基线结果 训练集分割率 测试集准确率n 微博 基线文件
85%
98.84%
20
weibo_baselines
50%
90.14%
20
15%
90.48%
20
“20条微博”数据集的词典有27890个token,每个不同的训练集都有不同的词典,比如训练集占数据集的85%时,词典里有25000个token,占15%时,词典里有10000个token。但是,即使测试集中有这么多未知的token(词汇),所有测试集的准确率仍然在90%以上。
无关
有兴趣的可以按照以下格式注释更多的数据集:
uid是水军吗?
532871947(潦草书写)
214839591(潦草书写)
或者其他情绪分析
uid 音乐艺术舞蹈...
532871947(潦草书写)
...
214839591(潦草书写)
...
UID音乐喜好度
532871947(潦草书写)
214839591(潦草书写)




 231118 巴索新语 你皱一下眉头我都心痛!爱与关怀的力量...
231118 巴索新语 你皱一下眉头我都心痛!爱与关怀的力量... 525心理健康节广播稿、国旗下讲话。525是什么?:\x26...
525心理健康节广播稿、国旗下讲话。525是什么?:\x26... 帮助你的,是一份情;拒绝你的,随风而逝。
帮助你的,是一份情;拒绝你的,随风而逝。